М.К. Рыбникова. Теория тестов: классическая, современная и "интеллектуальная"
Содержание
НЕСТАРЕЮЩАЯ КЛАССИКА
Item Response Theory (IRT) – английское название теории, которая достаточно широко используется в психологических и педагогических измерениях. На русский язык его переводят как «теория латентных черт», «теория тестовых заданий» и даже «теория пунктуальных ответов». Но в последнее время все чаще можно услышать другой – куда более вольный и смелый – перевод: «современная теория тестов». Ни больше ни меньше!
И пусть этот перевод и не отражает в полной мере оригинальное название, зато он вполне передает революционный порыв, связанный с внедрением IRT. В соответствии с ним, современная теория измерений способна преодолеть недостатки других теорий (в том числе и с помощью развитого математического аппарата) и решить очень многие возникающие проблемы. Но стоит ли теперь отказаться от Классической Теории Тестов (Classical Test Theory - CTT), которая также способна дать очень много полезных сведений, в пользу IRT? Постараемся ответить на этот вопрос на примере анализа одного из наших интеллектуальных тестов – ТИПС.
ПЛЮСЫ И МИНУСЫ
Сразу стоит сказать, что ни одна из теорий еще не исчерпала своих возможностей. Вопрос, прежде всего, следует ставить о достоинствах и об ограничениях каждого подхода.
Отметим для начала достоинства IRT-технологии:
- IRT (в частности, если мы говорим о теории Раша) превращает измерения, выполненные в дихотомических и порядковых шкалах, в линейные измерения, в результате качественные данные анализируются с помощью количественных методов.
- Мера измерения параметров модели Раша является линейной, что позволяет использовать широкий спектр статистических процедур для анализа результатов измерений;
- Оценка трудности заданий НЕ зависит от выборки испытуемых, на которых она была получена; исследователь получает возможность создания банков заданий, сбалансированных по трудности;
- Оценка уровня подготовленности испытуемых НЕ зависит от набора заданий. Соответственно, исследователь получает великолепную возможность более объективно сравнить баллы разных испытуемых по разным тестовым шкалам, суммировать эти баллы и выводить объективированные рейтинги;
- Неполнота данных (пропуск некоторых комбинаций «испытуемый - тестовое задание») не является критичной; это действительно весомый «плюс» IRT. (CTT уязвима в ситуации пропущенных значений, что фактически делает невозможным анализ данных тестирования по методикам, имеющим расширенные банки заданий).
Таким образом, можно говорить об улучшении качества анализа (благодаря использованию новых статистических процедур), о новых возможностях, которые открывает IRT. Но не лишена она и определенных недостатков:
- Модель IRT слаба в плане обеспечения внутренней согласованности теста. Необходимым условием применения модели IRT является изначальная согласованность тестовых пунктов, которые берутся в анализ.
- IRT-анализ предполагает необходимость использования большого массива данных (в среднем от 1000 испытуемых), а также требует использования сложного математико-статистического аппарата и специальных программных продуктов, что делает его достаточно трудоемким и дорогим методом.
Становится очевидно, что эффективная практика применения «современной теории» возможна лишь с опорой на «классическую теорию». Ведь именно в фокусе последней находятся многие интересующие разработчиков теста статистические вопросы (вплоть до показателей надежности и валидности теста). Поэтому имеет смысл рассматривать совместное применение двух теорий и всего арсенала доступных процедур анализа.
С помощью методов классической теории легко провести первичный анализ качественных характеристик варианта теста в целом, а уже затем с помощью IRT более подробно исследовать характеристики заданий. Наиболее эффективно использовать IRT в ситуациях, когда у нас уже есть сформированный (внутренне согласованный) банк тестовых заданий, разработанный в рамках CTT.
Одной из основных задач IRT является переход от индикаторных переменных к латентным параметрам.
В IRT фактически устанавливается связь между двумя латентными параметрами. 1 - это уровень подготовленности испытуемых ?i, где i - номер испытуемого, варьирующийся от 1 до N (если N - количество испытуемых). 2 - трудность j-го задания ?j, где j меняется от 1 до M (обозначим M как количество заданий в тесте).
В начале 50-х годов прошлого столетия датский математик G.Rasch стал рассматривать матрицу тестовых данных как результат взаимодействия множества испытуемых с множеством заданий. При этом естественным образом принималась аксиома - чем труднее задание для данного испытуемого, тем ниже вероятность правильного ответа. Из этой аксиомы неизбежно вытекало свойство функциональности модели: вероятность правильного ответа испытуемых на задание j есть функция от взаимодействия двух параметров – от уровня подготовленности испытуемых и от уровня трудности задания (?j). Графический образ такой функции представлен на рис. 2.
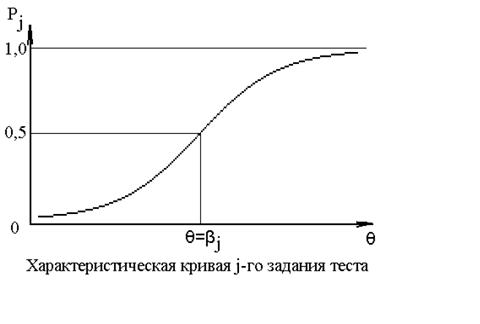
Рис. 2. Характеристическая кривая тестового задания.
Чем выше крутизна кривой задания, тем выше дифференцирующая способность задания. Включение в тест заданий с пологими характеристическими кривыми не всегда целесообразно: задания могут измерять, помимо интересующего свойства, ещё и какое-то другое.
ОСНОВНЫЕ ДОПУЩЕНИЯ IRT:
- 1) существуют латентные/скрытые параметры личности (которые недоступны для непосредственного наблюдения). Например, в интеллектуальном тестировании - это уровень подготовленности испытуемого и уровень трудности задания);
- 2) существуют индикаторы, которые связаны с латентными параметрами, но в отличие от них, доступны для наблюдения. По значениям индикаторов можно судить о значениях латентных параметров;
- 3) оцениваемый латентный параметр должен быть одномерным (шкала должна измерять одну и только одну переменную.) Если условие одномерности не выполняется, то необходимо работать над тестом, проверить согласованность заданий, размерность теста и т.д. Все задания, которые нарушают гомогенность, должны быть исключены из шкалы.
! Мы указали только самые общие допущения IRT. Существуют и другие, связанные с математико-статистическим аппаратом для обработки эмпирических данных.
ТЕОРИЯ И ПРАКТИКА
В фокусе исследований IRT находится, прежде всего, проверка формальных свойств заданий для повышения точности измерения, принятия решения о включении проверяемых заданий в тест: построение характеристических кривых заданий, проверка размерности теста и согласия данных с моделью.
Приведем пример использования IRT-анализа на примере теста ТИПС (его полное название – «Тест интеллектуального потенциала стандартизированный»).
! Все расчеты производились с помощью специального программного обеспечения для модели Раша (Winsteps 3.75).
В первую очередь, стоит посмотреть на общие статистики по каждой шкале (здесь и далее рассматривается шкала «Вычисления») – рис.3.
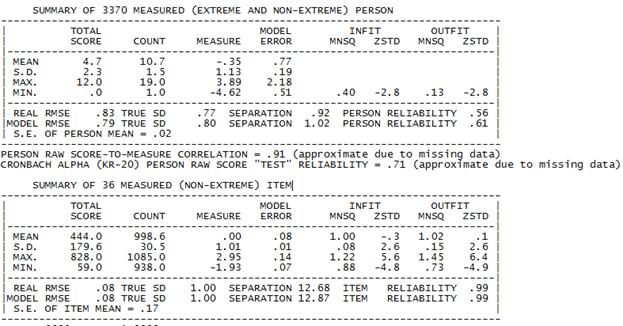
Рис.3. Общие статистики (Summary statistics).
Обращает на себя внимание высокий показатель внутренней согласованности (Альфа Кронбаха) – 0,71, что закономерно, т.к. тестовые задания были отобраны с использованием CTT (то есть можно сказать, что задания были изначально согласованы). Мы использовали большую выборку (3370 человек). Данная выборка была признана достаточной для проведения анализа (показатель item reliability).
Одной из главных задач теста является измерение латентной переменной (собственно, исследуемого конструкта). Однако здесь встает вопрос – как узнать, что данная шкала свободна от смешений с побочной переменной. IRT предлагает нам способ определить размерность шкалы (рис.4).
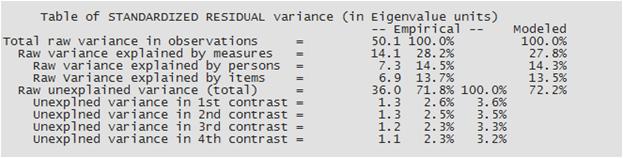
Рис. 4. Определение размерности (Dimensionality).
В данном случае шкала измеряет только одну латентную переменную и свободна от смешений. Что делать, если обнаруживается вторая размерность? На рисунке 5 изображена таблица исследования размерности шкалы и цветом обозначена выявленная в анализе вторая размерность (о появлении второй размерности можно говорить, если значение «unexplned variance in 1st contrast» > 2.0). Дальнейшая работа со шкалой будет предполагать поиск заданий, дающих вторую размерность, и исключение смешений из теста.
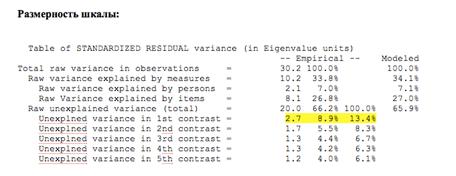
Рис.5. Определение размерности (Dimensionality).
Многих разработчиков интересует вопрос трудности заданий и их распределение на шкале (Достаточно ли трудных заданий? Или тест содержит слишком много легких заданий?). На эти вопросы может ответить карта заданий и респондентов (рис.6).
Можно сказать, что распределение заданий в шкале Вычисления является оптимальным, однако, есть и что улучшать. Можно заметить, что задание 21 (v_21) является слишком сложным и его следует исключить, а простых заданий (как 7-ое) в тесте, напротив, можно добавить. Обновление методики будет предполагать написание новых заданий (аналогичных 7-ому), сбор данных по новой версии и повторный расчет внутренней согласованности теста (в рамках CTT), за которым последует IRT-анализ.
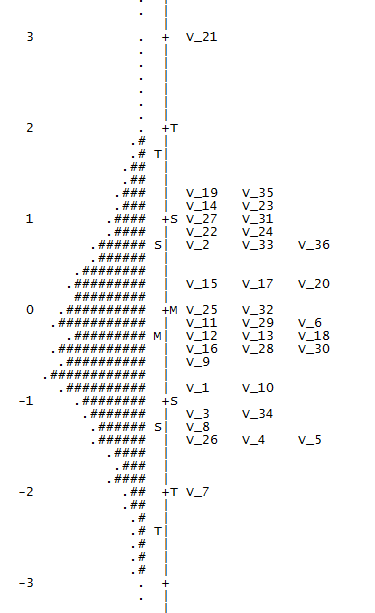
Рис.6. Карта заданий и респондентов (слева распределение респондентов, справа – заданий, относительно шкалы логитов, где +M – средняя трудность/подготовленность).
Конечно, мы перечислили далеко не все возможности IRT анализа (как минимум, стоит упомянуть проверку заданий на согласие с моделью и построение характеристических кривых для вопросов), мы назвали лишь самые общие и простые возможности улучшить классический анализ теста.
Таким образом, мы на практике убедились в продуктивности IRT-подхода. Как и в необходимости предварительного анализа средствами СТТ. Впрочем, не менее любопытен и другой факт: созданный сугубо в русле классической теории ТИПС с честью выдержал проверку средствами IRT.
ЛИТЕРАТУРА
1. Hambleton, R.K., & Swaminathan, H. Item response theory: Principles and application. Boston: Kluwer-Nijhoff, 1985.
2. Handbook of test development/edited by Steven M. Dowing, Thomas M. Haladyna. – 2006 by Lawrence Associates, Inc. 778 p.
3. Аванесов В. А. «ITEM RESPONSE THEORY: основные понятия и положения».
4. Батурин Н.А., Мельникова Н.Н. Технологии конструирования тестов.
5. Батурин Н.А., Мельникова Н.Н. Технология разработки тестов: часть I //Вестник ЮУрГУ. Серия "Психология". 2009. Вып. 6. - С. 4-14.
6. Карданова Е.Ю. Преимущества современной теории тестирования по сравнению с классической теорией тестирования. Вопросы тестирования в образовании. 2004, № 10.
7. Сорокина О.Л., Романюк Э.И., Тимохин В.В. Современная теория сложности задании в психологии, Москва 2004.
Похожие статьи


Показатели интеллекта обладают высокой предсказательной способностью результатов, связанных с работой и карьерой. В статье расскажем, как оценить интеллектуальные способности персонала и чем это полезно для бизнеса.

В целом, ошибки — это нормально, все иногда ошибаются. Но как заранее узнать: невнимательность у сотрудника — это редкость или норма? В статье расскажем, как тесты на внимание помогают спрогнозировать внимательность каждого сотрудника в компании.



Широкое внимание привлекло появившееся в конце прошлого месяца в Интернете сообщение о связи IQ и использования определенного браузера. Рунет радостно откликнулся заголовками в ассортименте: «Ваш IQ зависит от Интернет-браузера», «Выбор браузера зависит от уровня интеллекта пользователя», «Пользователи браузера Internet Explorer … оказались самыми недалёкими …глупее остальных …глупее юзеров Opera!», «Internet Explorer назвали браузером для тупых», «Самые умные пользователи предпочитают Opera» и т.п. Оставим подобные выражения на совести журналистов и обратимся к отчету наших канадских коллег, консалтинговой компании AptiQuant Psychometric Consulting Co., работающей с психометрическими тестами.


В нашем арсенале более 30 тестов оценки личностных, мотивационных особенностей, IQ, управленческого потенциала, рискованного поведения, самопознания и др.
Оставьте заявку на бесплатную консультацию специалиста!
